Unlocking Git: Demystifying the .git Folder and Its Inner Workings
The day I accidentally deleted .git and understood everything
You know that moment when you break something and suddenly everything makes sense? That was me with the .git folder.
It was 2022. I'd been using Git for about a year, felt comfortable with the basics. Then while cleaning my project, I saw this .git folder taking up 200MB. "Hidden folder? Probably just cache," I thought. So I deleted it.
My entire Git history vanished. Every commit, every branch, everything – gone. The files were still there, but Git acted like they never existed. That's when it hit me: Git isn't magic. It's just clever file management. And everything lives in that .git folder I just nuked.
Let me show you what I learned the hard way.
Understanding the .git Folder: Git's Entire Universe
When you run git init, Git creates a .git folder in your project directory. That's literally all it takes for your folder to become a Git repository. This single hidden folder is Git's entire universe – every commit, every branch, every piece of history lives here.
Delete .git? You delete Git. The folder stops being a repository. Your files stay, but Git forgets they ever existed.
Let's peek inside:
ls -la .git/
You'll see:
HEAD → Points to your current location
config → Repository settings
objects/ → Where all your data lives
refs/ → Branch and tag pointers
index → The staging area
hooks/ → Automation scripts
Everything Git knows about your project is in these files and folders. No external database, no hidden cloud storage. Just files on your disk.

How Git Actually Works: It's All About Hashes
Here's the core concept that changed everything for me: Git doesn't store files by name. It stores them by content.
When you add a file to Git, it does this:
Reads the file content
Calculates a SHA-1 hash of that content
Compresses the content
Stores it using the hash as the filename
Let's say you have a file hello.txt with "Hello World" inside. Git calculates its hash: 557db03de997c86a4a028e1ebd3a1ceb225be238. It then stores the compressed content at:
.git/objects/55/7db03de997c86a4a028e1ebd3a1ceb225be238
The beautiful part? Same content = same hash = stored only once. Have the same file in 50 commits? Git stores it once. This is how Git stays efficient even with massive histories.
The hash also guarantees integrity. Change even one character, and you get a completely different hash. Git instantly knows if data got corrupted.
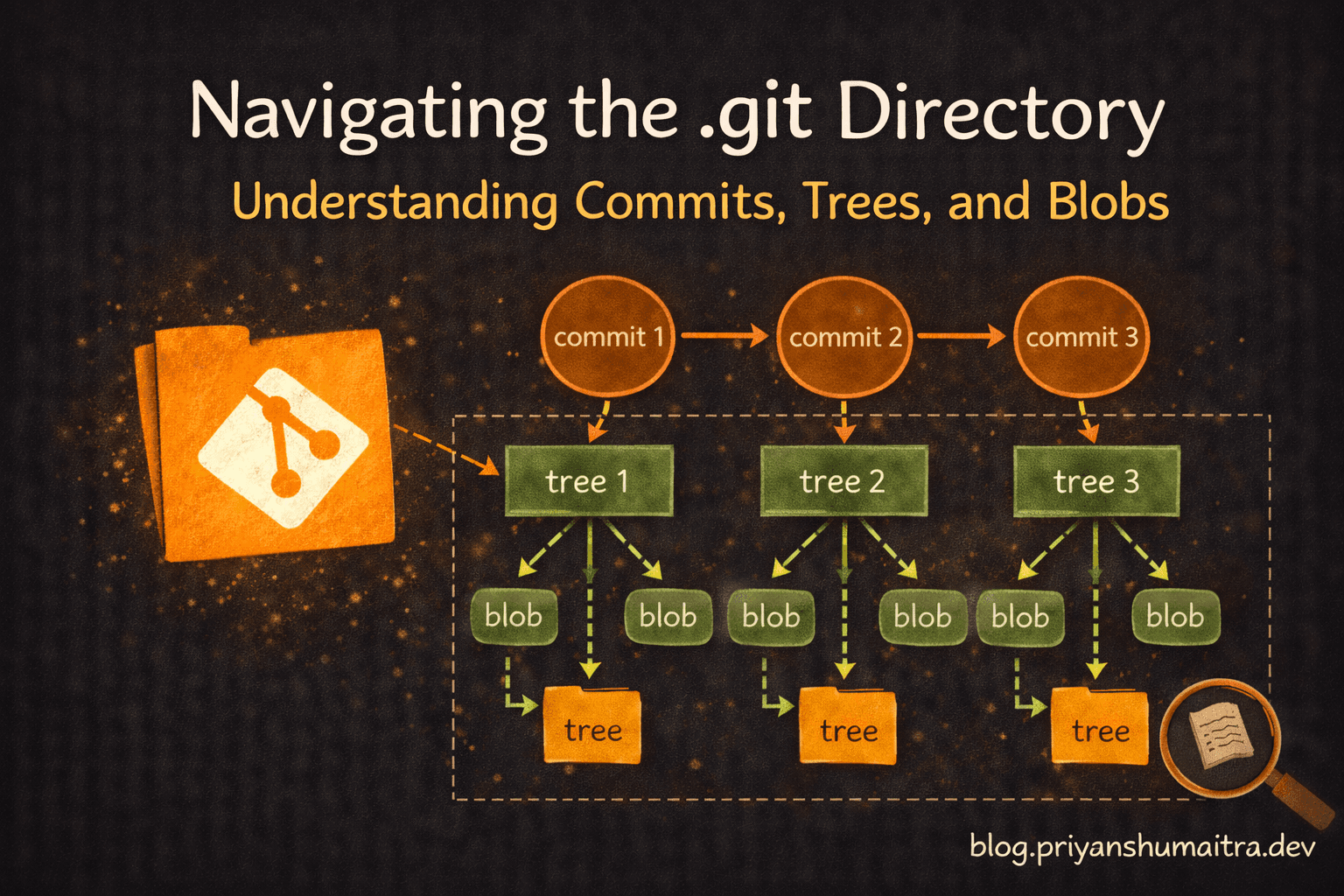
Git Objects: The Building Blocks
Git stores everything as objects. Three types: blobs, trees, and commits.
Blob Objects: Your file contents. No filename, no structure – just raw content, compressed and hashed. When you git add readme.md, Git creates a blob with that file's content.
Tree Objects: Your directory structure. Contains blob references (files), other trees (subdirectories), filenames and permissions. Like a folder inventory.
Commit Objects: Your snapshots. Contains a tree pointer, parent commit pointer, author info, and message. The commit doesn't hold files – it points to them via the tree.

git cat-file -p HEAD
Shows:
tree 4b825dc642cb6eb9a060e54bf8d69288fbee4904
parent 8f3d3e8a9c7b4e5f6a2d1c3b4a5e6f7a8b9c0d1e
author Your Name <you@example.com> 1638360000 +0530
Add login feature
Each commit knows its parent, creating a chain – your project's history.
What Happens During git add: Building the Index
The staging area confused me for months. Then I understood what git add actually does.
When you run git add app.js:
Git reads your file content
Creates a blob object
Calculates its hash
Stores it in
.git/objects/Updates
.git/indexwith this blob's hash
The index is a binary file mapping filenames to blob hashes. It's a draft of your next commit. Modified five files? Add three, commit them. The staging area gives you this control.
What Happens During git commit: Saving the Snapshot
When you run git commit -m "Add feature":
Reads the index to see what's staged
Creates tree objects for your directory structure
Creates a commit object with tree reference, parent commit, author info, and message
Stores the commit in
.git/objects/Updates current branch reference to point to new commit
That last step is key. Branches are just pointers to commits. When you're on main, there's a file at .git/refs/heads/main with a commit hash. Committing updates this file.
cat .git/refs/heads/main
8f3d3e8a9c7b4e5f6a2d1c3b4a5e6f7a8b9c0d1e
That's your entire branch – a 40-character hash in a text file.
How Git Tracks Changes: It Doesn't
Here's something that blew my mind: Git doesn't track changes. It tracks snapshots.
When you commit, Git doesn't store "changed line 15 in app.js". It stores a complete snapshot of your entire project at that point in time. Every commit is a full project snapshot.
"Wait," I thought when I learned this, "doesn't that waste tons of space?"
No, because of content-addressing. Remember, Git stores objects by their content hash. If a file doesn't change between commits, both commits point to the same blob object. No duplication.
You have 100 files, change one, and commit? Git creates:
One new blob (the changed file)
New tree objects for affected directories
One new commit object
The other 99 files? Same blobs, same hashes, already in
.git/objects/
When you run git diff, Git compares two snapshots and shows you the differences. But those differences aren't stored – they're calculated on the fly.
This is why Git can show you any version of your project instantly. It's not replaying changes – it's checking out a snapshot.
Branches Are Just Pointers
A branch is a text file containing a commit hash. That's it.
git branch feature-login
This creates .git/refs/heads/feature-login with the current commit's hash. No files copied. Just a 41-byte text file.
Switching branches? Git updates HEAD, reads the commit hash, updates your working directory. Instant and lightweight.
HEAD is also a pointer:
cat .git/HEAD
ref: refs/heads/main
When you commit, Git follows HEAD to the branch, creates the new commit with the old commit as parent, and updates the branch reference.
Building Your Mental Model
Understanding Git internals gave me a clear mental model:
Working directory: Your workspace for editing files.
Index (.git/index): Your draft. git add moves changes here.
Repository (.git/objects/): Published work. git commit makes drafts permanent.
Branches: Bookmarks pointing to commits. Cheap and disposable.
Commits: Snapshots forming a chain through parent references.
Everything is in .git/. Nothing's in the cloud unless you push. No magic – just files and pointers.
Why This Matters
Understanding that branches are pointers removes the fear of branching. They cost nothing.
Understanding commits as snapshots explains why jumping between commits is instant.
Understanding the staging area shows it's giving you control, not adding friction.
Understanding object storage explains why Git excels with code (small text files) but struggles with videos or binaries (huge blobs).
And when things break, you know your data's in .git/objects/, recoverable with git reflog.
The Recovery Story
Remember when I deleted .git? That was my personal project. Annoying but recoverable from my last push.
But months later, a teammate ran a bad rebase that scrambled our branch. Everyone panicked. We thought days of work were lost.
I knew better. Everything was in .git/objects/. I used git reflog to find where HEAD was before the bad rebase:
git reflog
Found the commit hash we needed, created a new branch pointing to it:
git branch recovery abc1234
Everything recovered in two minutes. My teammates thought I was a wizard. I just understood the model.
The .git Folder Is Everything
These days, I treat .git/ as sacred. Project files? Those are just the current state. I can regenerate them from any commit. But .git/? That's the entire history. Every commit, every branch, everything.
Some people exclude .git/ from backups to save space. I do the opposite. I'll lose working directory over .git/ any day. With the repository, I can restore anything. Without it, I have nothing.
And I never delete hidden folders to "save space" anymore. Learned that lesson well.
Understanding Git's internals transformed it from a tool I feared breaking to a system I could reason about. Next time you run a Git command, picture what's happening in .git/. It makes everything make sense. Git isn't magic – it's just clever file management with pointers and hashes. And once you get that, you get Git.